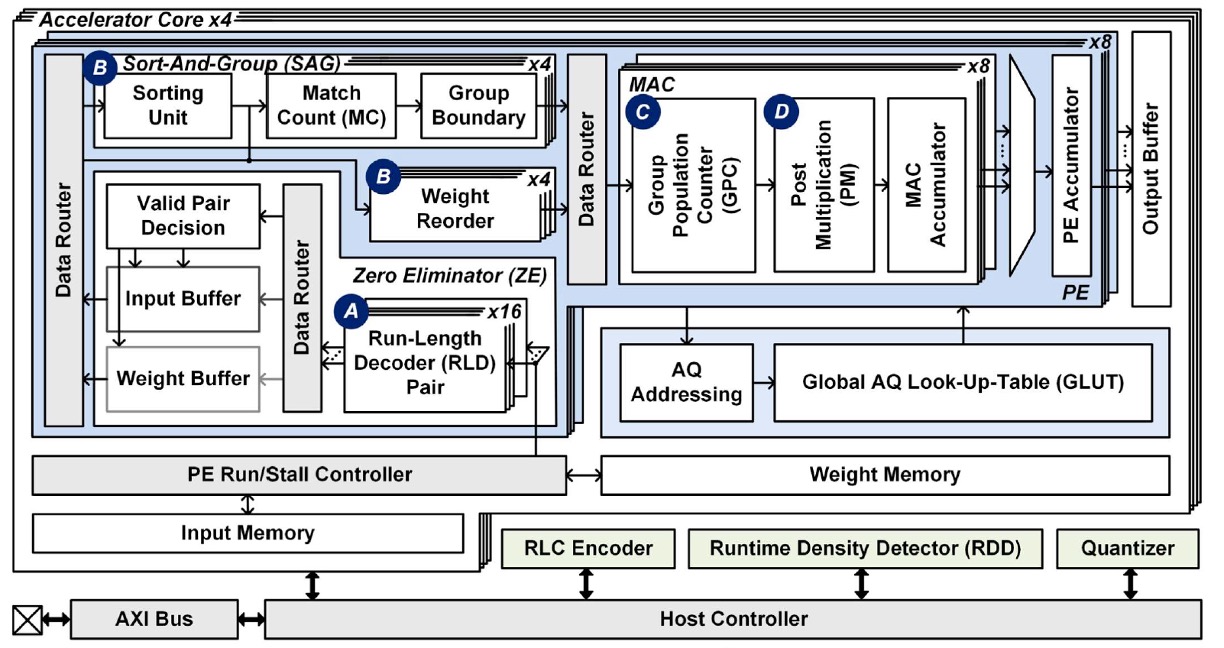
Data Processing Innovation
We explore various hardware-software co-design approaches to maximize computing efficiency for deep learning workloads. For instance, although arbitrary quantization algorithms have been proposed to maximally reduce bitwidth, most existing solutions still require decoding into full precision for computation. We propose a hardware architecture that efficiently supports arbitrary quantization without decoding.
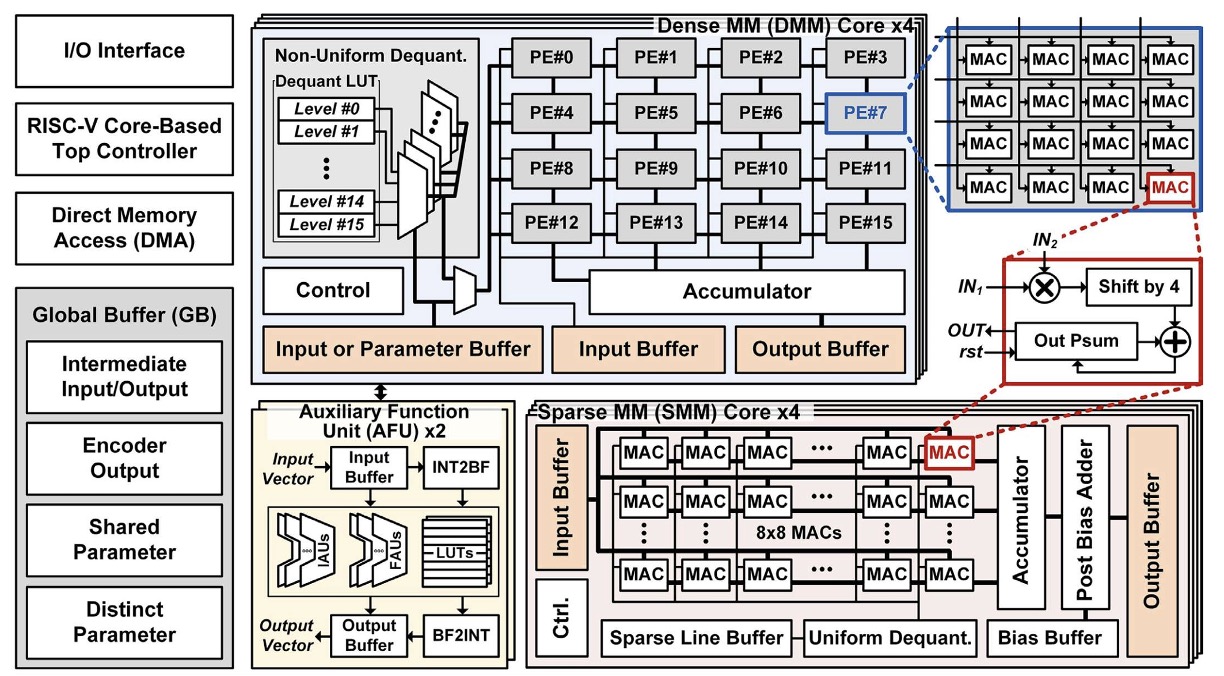
Data Movement Innovation
Our goal is to reduce off-chip memory access by optimizing data movement across the system. As an example, we introduce a novel shared parameter technique for transformer models, which consolidates common parameters on-chip while storing distinct parameters in a highly sparse format off-chip. This method significantly cuts down data transfers and memory footprint.
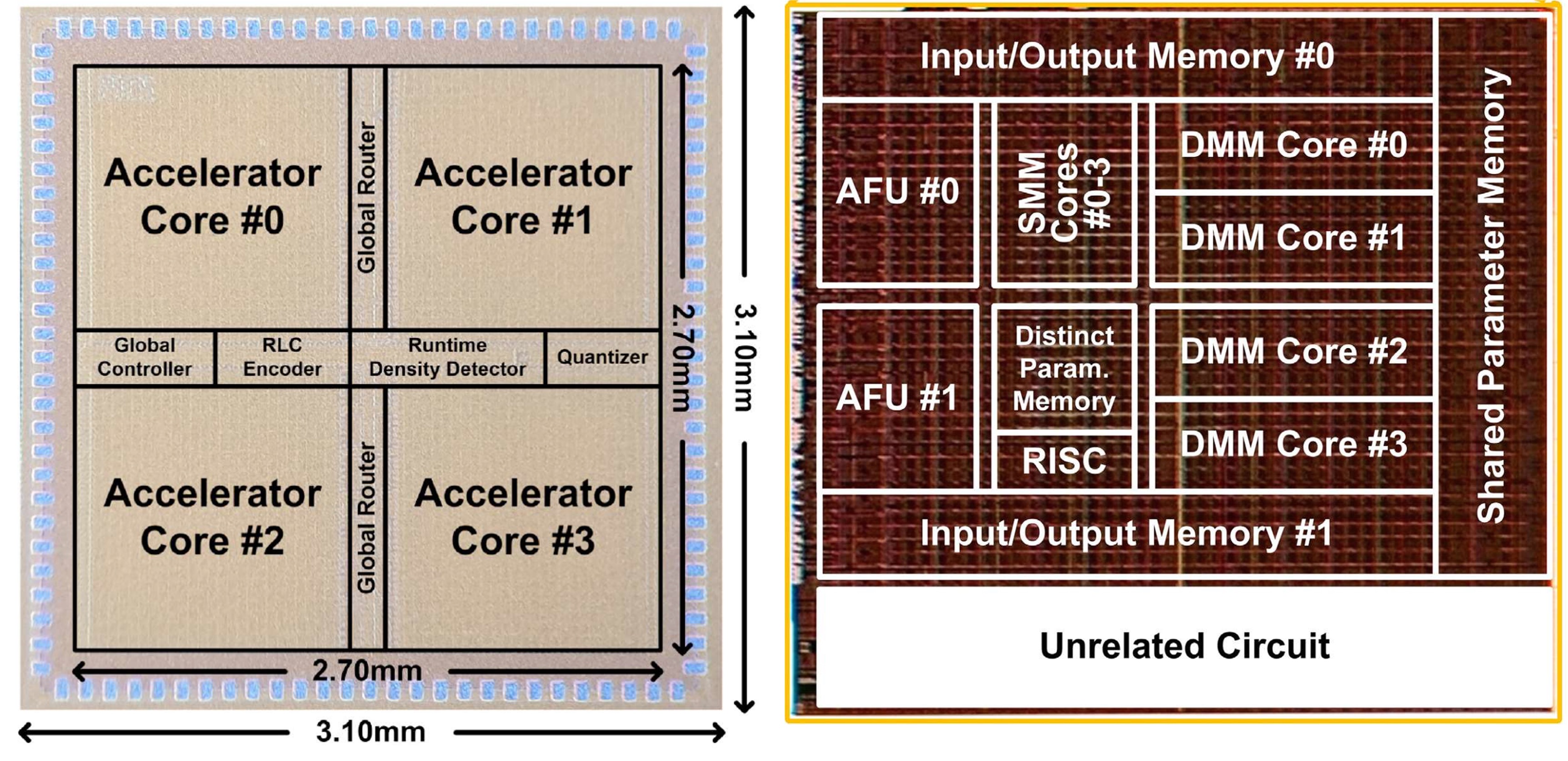
Chip Design
To bring our innovative architectural concepts to life, our lab focuses on custom chip design for intelligent systems. We integrate specialized logic, advanced memory hierarchies, and efficient communication interfaces into a single system-on-chip (SoC) platform to deliver accelerated application. Moreover, we fabricate actual chips to rigorously demonstrate the feasibility and reliability of our proposed architecture. From circuit-level optimizations such as low-power SRAM arrays and voltage scaling to architectural strategies like pipeline parallelism and advanced caching, our chip prototypes validate our designs and pave the way for the next generation of on-device intelligent systems.